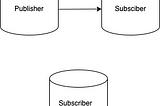
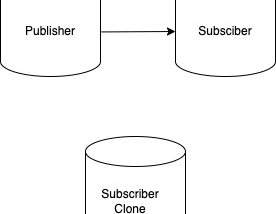
Virender SinglaPostgreSQL: Cloning your instance can mess up replicationMany times we need to clone a production instance for some testing purpose. For example, validate a major version upgrade on a clone…3 min read·Apr 11, 2024----
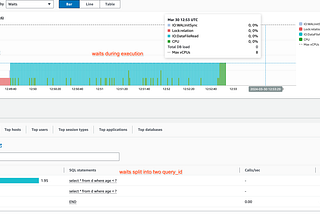
Virender SinglaPeek into Query Hash (query_id) in PostgreSQLPostgreSQL has an extension called pg_stat_statements to track top SQLs and it has queryid and query columns since ever (at least since I…3 min read·Mar 30, 2024----
Virender SinglaUnderstand SQL Query execution more closely: PostgreSQL Operator and CastIn RDBMS, a query execution goes through a number of steps like syntax and semantic checks, generate a parse tree with an optimized plan…5 min read·Mar 30, 2024----
Virender SinglaPostgres — Logical Replication and long running transactionsI was exploring logical replication in Postgres with respect to long running transactions and see how it replicates/behaves in different…6 min read·Dec 16, 2021----
Virender SinglainNerd For TechPostgres — Parallel jobs with PythonRecently our team got multiple notifications from AWS for our Postgres Aurora clusters regarding deprecation of Postgres v9.6.x. We must…2 min read·Apr 12, 2021----
Virender SinglainNerd For TechPostgres — Good for Queuing implementation?Few days back we got CloudWatch alarm alert for CPU Utilization for one of the Postgres database hosted on Amazon Aurora. Looking at…5 min read·Apr 9, 2021--2--2
Virender SinglainNerd For TechPostgres — Partial Index usage with Dynamic date filterRecently I was working on a slow running query. AS usual I checked different bind variables passed for that query and the count for those…3 min read·Apr 2, 2021----